📌 项目背景
在企业知识管理场景中,传统的关键词搜索存在语义理解不足、上下文丢失、多轮对话能力弱等问题。 员工在查找内部文档、技术规范、业务流程时,往往需要多次尝试不同的关键词组合。
本项目基于 LangChain + GPT-4 构建了一套完整的 RAG(Retrieval-Augmented Generation)系统, 通过向量检索 + 大语言模型生成的方式,实现了精准的语义问答和智能对话。
💡
核心价值: 将企业散落的知识文档转化为可对话的智能助手,员工只需用自然语言提问,系统即可从海量文档中精准检索并生成专业回答,大幅提升知识获取效率。
🔄 RAG 核心流程
RAG系统的核心在于将检索与生成相结合,通过多路检索获取相关上下文,再由大语言模型生成精准回答。
📄 文档入库
→
✂️ 智能分块
→
🔢 向量化
→
🗄️ 向量存储
→
🔍 语义检索
→
🤖 LLM生成
🏛️ 系统架构
系统采用前后端分离架构,后端按职责分为框架层、AI基础设施层、业务层三个模块,实现高内聚低耦合。
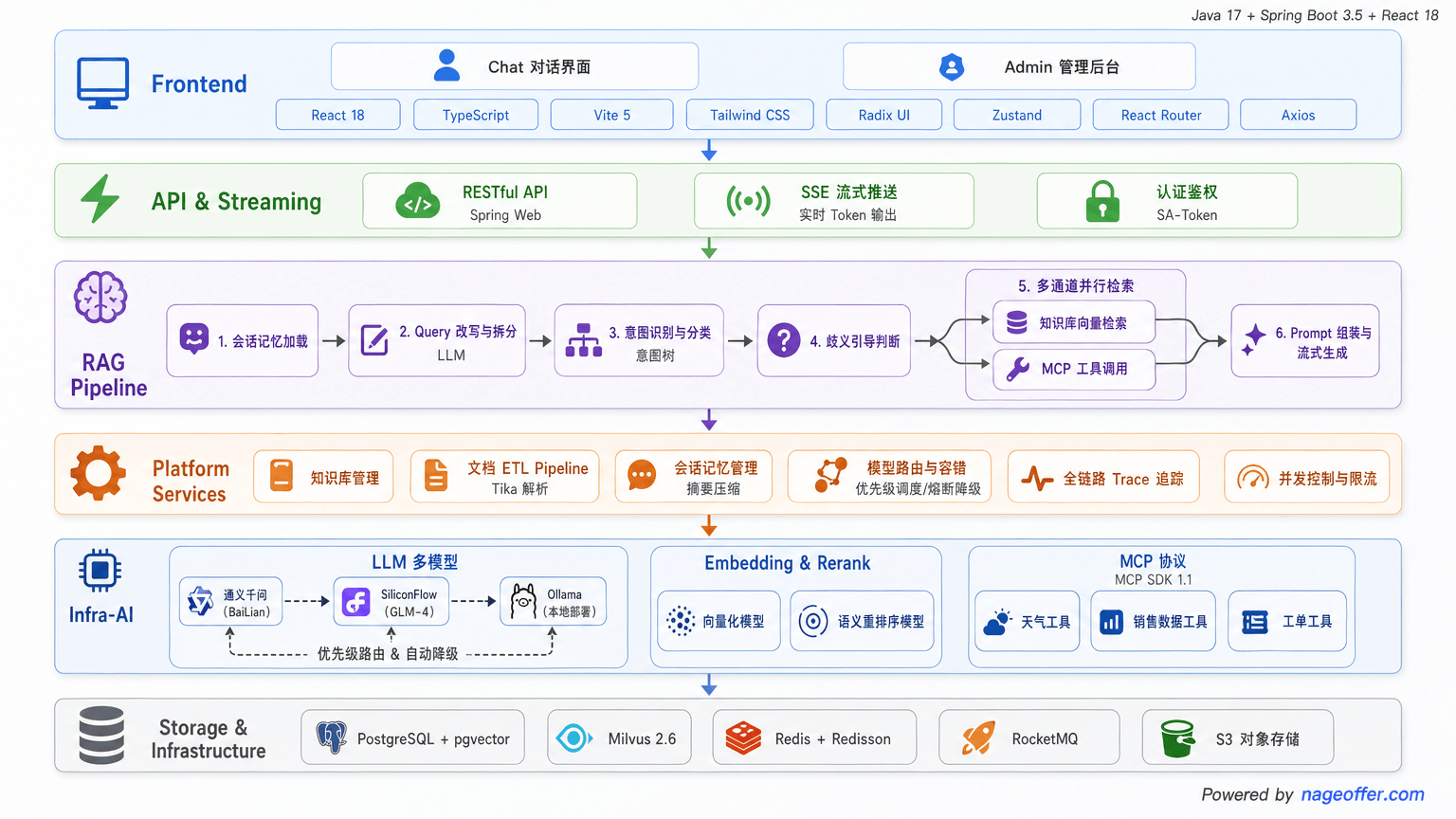
图1:系统整体架构 — 多层设计,模型与业务解耦
| 模块 | 职责 | 核心技术 |
|---|---|---|
| Framework 层 | 通用基础能力,异常处理、链路追踪、限流 | Spring Boot、AOP、Redis |
| Infra-AI 层 | 屏蔽模型供应商差异,统一对接接口 | LangChain、OpenAI API、向量数据库 |
| Bootstrap 层 | 业务逻辑处理,意图识别、检索策略 | FastAPI、Prompt Engineering |
🔍 多路检索架构
为了兼顾精准匹配与语义召回,系统采用多通道并行检索 + 后处理流水线的架构设计。
向量检索
基于Embedding的语义相似度检索,理解用户意图,召回语义相关的文档片段。
关键词检索
传统BM25算法,精确匹配关键词,适合订单号、产品编号等精确查询场景。
混合检索
多路结果融合排序,综合语义相关性和关键词匹配度,输出最优结果。
重排序
对检索结果进行二次精排,使用Cross-Encoder模型提升最终排序质量。
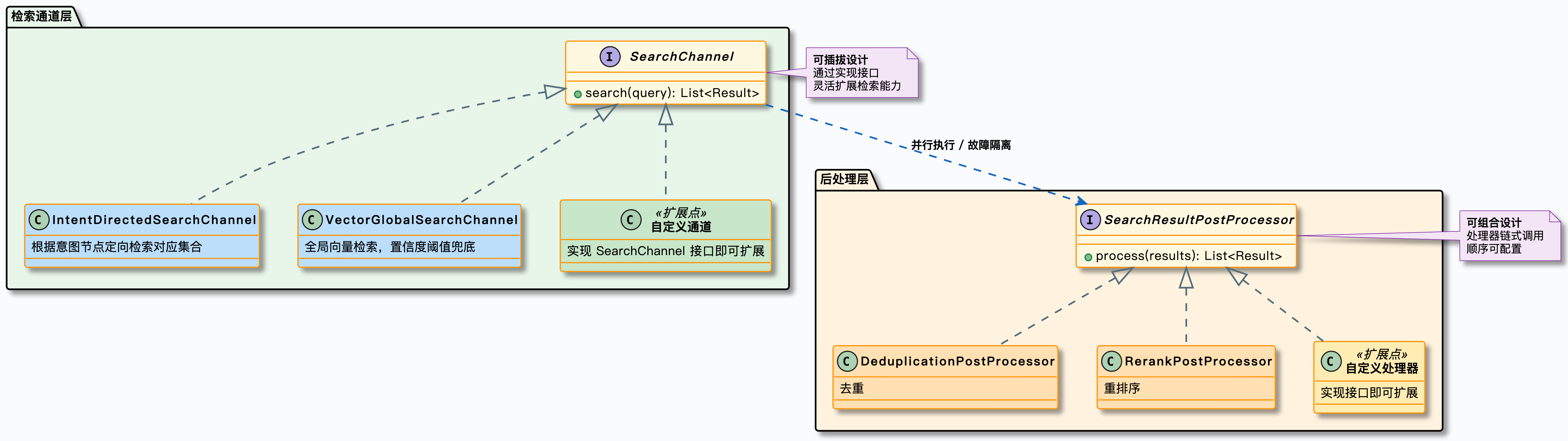
图2:多路检索架构 — 并行检索 + 后处理流水线
✨ 核心功能
🧠 意图识别
树形多级意图分类,置信度不足时主动引导澄清,准确路由到对应处理链路。
💬 多轮对话
上下文记忆管理,支持滑动窗口 + 自动摘要压缩,长对话不丢失关键信息。
🔧 工具调用
MCP协议集成,非知识类意图自动调用业务工具,检索与工具无缝融合。
📝 问题重写
用户问题自动重写与拆分,补全上下文信息,提升检索召回率。
⚡ 模型容错
多模型路由 + 三态熔断器,模型故障自动降级,服务不中断。
📊 全链路追踪
基于AOP的Trace机制,每个环节耗时、输入输出、异常信息完整记录。
🖥️ 系统界面预览
1 问答首页
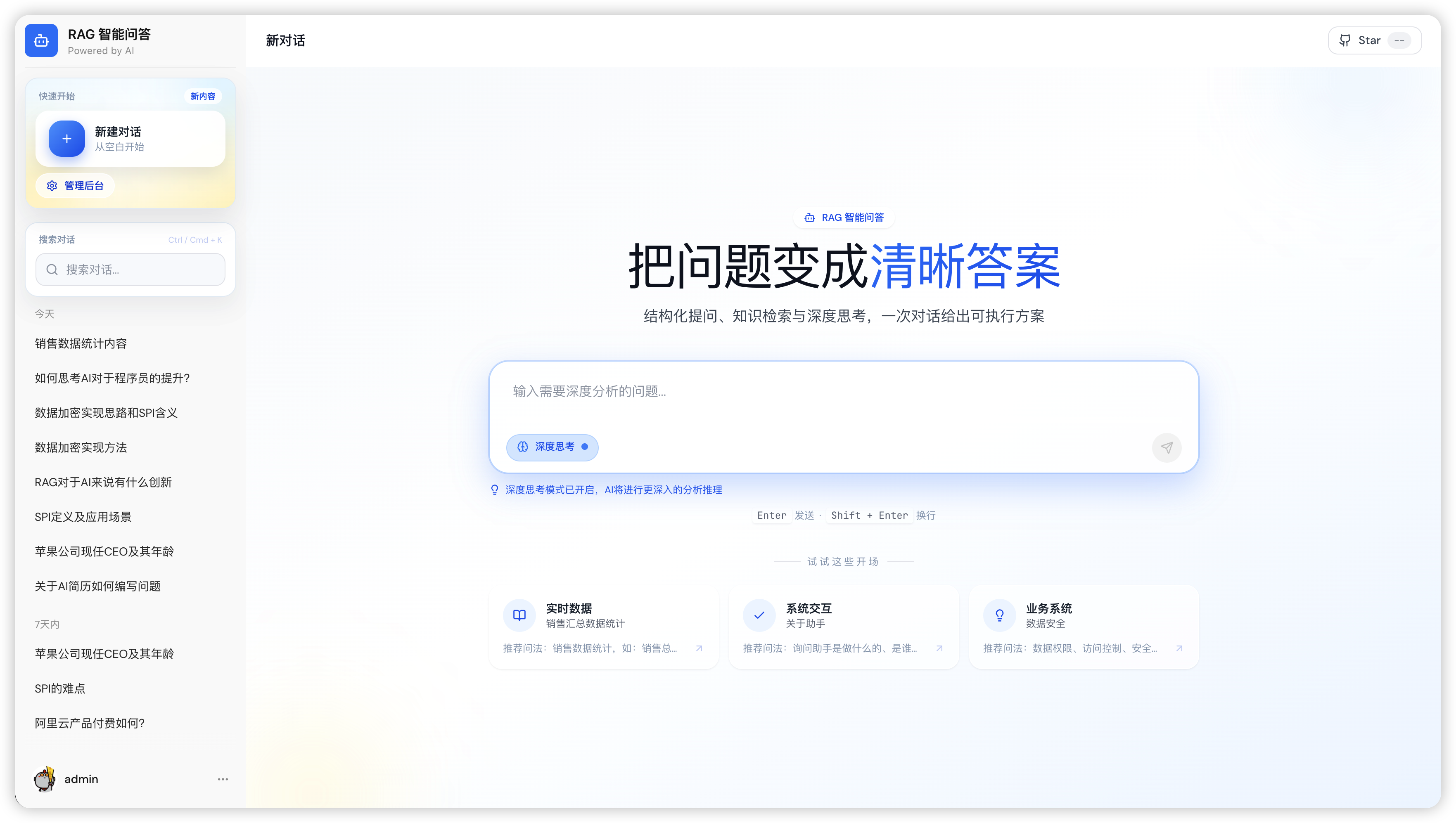
图3:问答首页 — 简洁直观的对话入口
支持自然语言输入、示例问题快速填充、深度思考模式
支持自然语言输入、示例问题快速填充、深度思考模式
2 智能问答
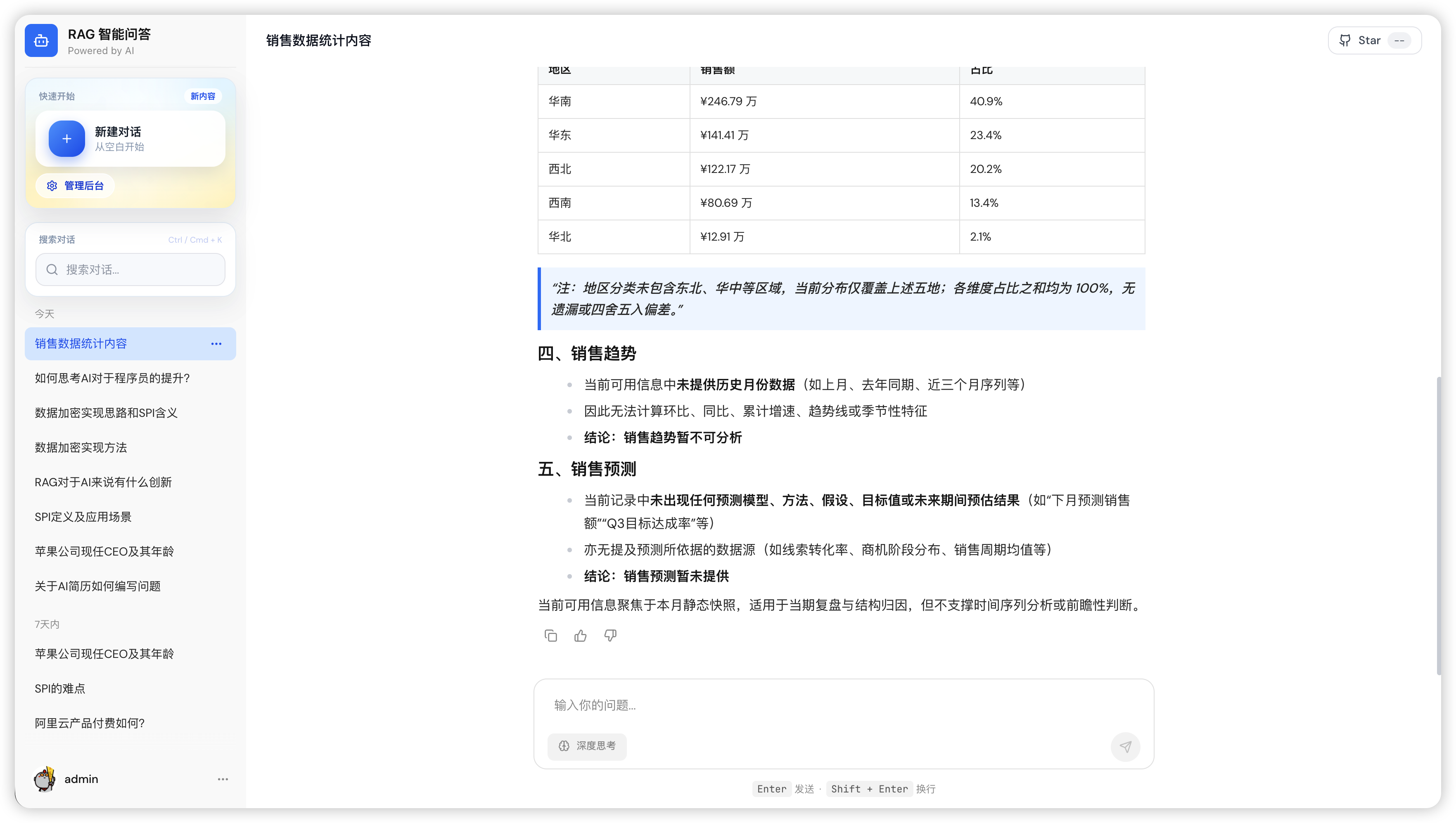
图4:智能问答界面 — 实时流式生成回答
支持Markdown渲染、代码高亮、回答评价(点赞/点踩)
支持Markdown渲染、代码高亮、回答评价(点赞/点踩)
3 知识库管理
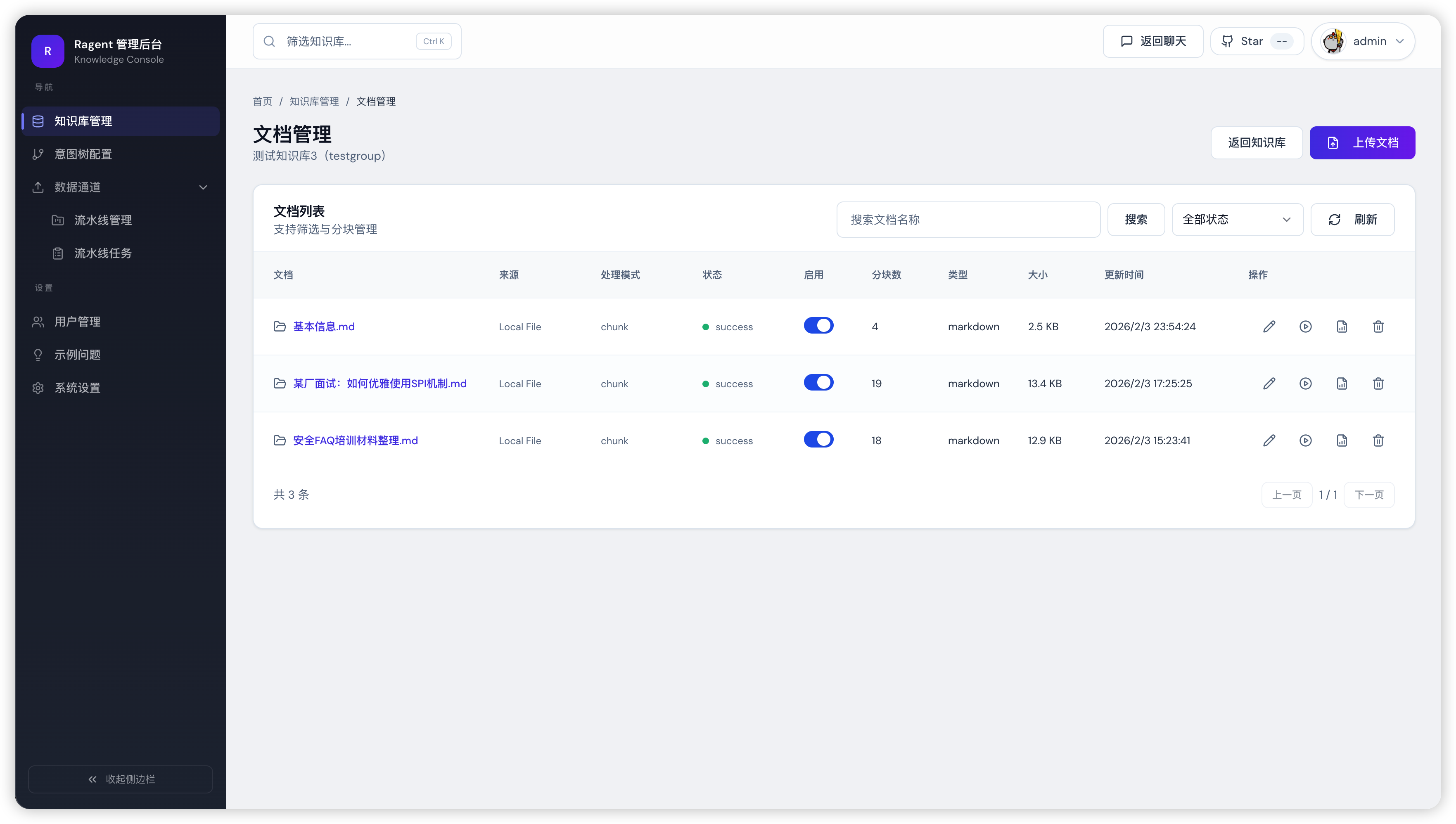
图5:知识库管理 — 文档入库与分块监控
可视化Pipeline执行过程,支持增量更新和分块策略配置
可视化Pipeline执行过程,支持增量更新和分块策略配置
4 RAG处理链路
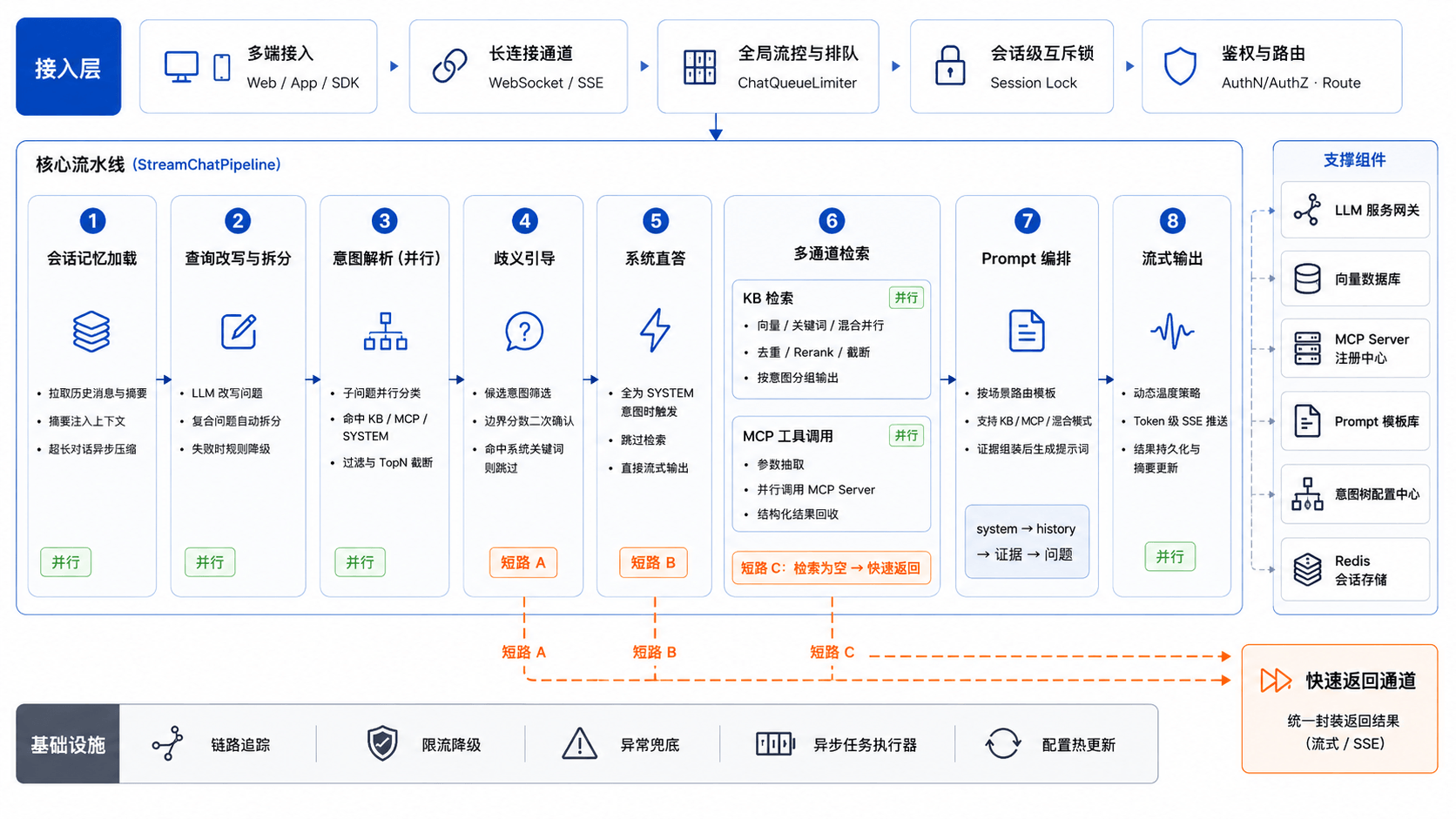
图6:RAG处理链路 — 一次用户提问经过的核心流程
从问题重写、意图识别、多路检索到最终生成,每个环节都有详细Trace
从问题重写、意图识别、多路检索到最终生成,每个环节都有详细Trace
5 管理后台
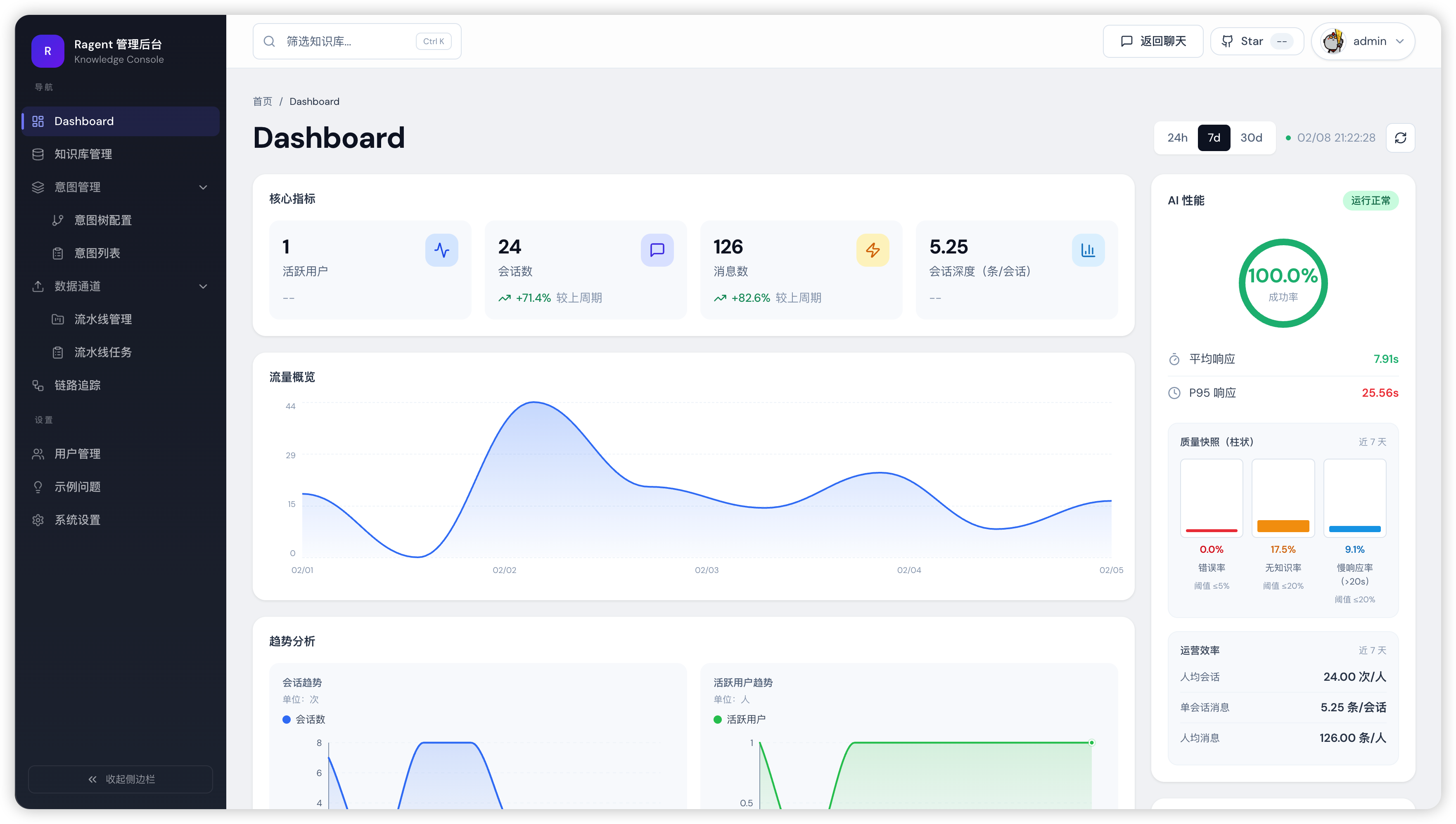
图7:管理后台 — 完整的可视化控制台
仪表板、模型管理、链路追踪、用户管理,覆盖运维全场景
仪表板、模型管理、链路追踪、用户管理,覆盖运维全场景
🛠️ 技术栈
GPT-4
大语言模型
LangChain
AI应用框架
Pinecone
向量数据库
FastAPI
后端框架
| 类别 | 技术选型 | 说明 |
|---|---|---|
| 后端框架 | FastAPI + Python | 高性能异步框架,支持流式响应 |
| AI框架 | LangChain | RAG链路编排、Agent构建、工具调用 |
| 大语言模型 | GPT-4 / DeepSeek | 多模型路由,支持自动降级 |
| 向量数据库 | Pinecone / ChromaDB | Embedding存储与向量检索 |
| 前端框架 | React 18 | 响应式UI,Markdown渲染 |
| 会话存储 | Redis | 会话记忆、上下文缓存 |
| 可观测性 | 全链路Trace | AOP埋点,每个环节完整记录 |
🎨 设计模式应用
项目中大量应用设计模式解决实际工程问题,每个模式都对应具体的扩展性或解耦需求。
| 设计模式 | 应用场景 | 解决的问题 |
|---|---|---|
| 策略模式 | SearchChannel、PostProcessor | 检索通道、后处理器可插拔替换 |
| 工厂模式 | IntentTreeFactory | 复杂对象的创建逻辑集中管理 |
| 注册表模式 | MCPToolRegistry | 组件自动发现与注册 |
| 责任链模式 | 后处理器链、模型降级链 | 多个处理步骤按顺序串联 |
| 观察者模式 | StreamCallback | 流式事件的异步通知 |
| 装饰器模式 | ProbeBufferingCallback | 在不修改原有回调的前提下增加能力 |
💎 核心价值对比
| 维度 | 传统搜索 | 本系统 |
|---|---|---|
| 检索方式 | 关键词精确匹配 | 多路语义检索 + 重排序 |
| 理解能力 | 无法理解语义 | 深度语义理解,支持同义词、上下文 |
| 对话能力 | 单次查询,无记忆 | 多轮对话,上下文记忆 |
| 回答质量 | 返回文档列表 | 生成精准、结构化的回答 |
| 扩展性 | 固定功能 | 支持工具调用、意图识别、自动降级 |
🌟 项目亮点
🚀
企业级特性:
- 多路并行检索 + 后处理流水线,兼顾精准与召回
- 树形意图识别体系,置信度不足主动引导澄清
- 多模型路由 + 三态熔断器,模型故障自动降级
- 滑动窗口 + 自动摘要压缩,长对话不丢失上下文
- 全链路Trace,每个环节耗时、输入输出完整记录
- MCP协议集成,非知识类意图自动调用业务工具
📊
工程质量:
- 分层架构设计,框架层 / AI基础设施层 / 业务层职责清晰
- 6种设计模式实战应用,解决扩展性与解耦问题
- 独立线程池管理,8个专用线程池 + TTL上下文透传
- 分布式限流,基于Redis信号量 + ZSET排队机制